http://www.monografias.com/trabajos30/inferencia-estadistica/inferencia-estadistica.shtml
Se sugiere Revisar el link ya que etse muestra un resumen de toda la amteria expuesta en este semestre o gran parte de ella, relacionado ala inferencia estadistica.
miércoles, 5 de diciembre de 2012
pruebas de hipotesis para una muestra
INTRODUCCION
Dentro del estudio de la inferencia estadística, se describe como se puede tomar una muestra aleatoria y a partir de esta muestra estimar el valor de un parámetro poblacional en la cual se puede emplear el método de muestreo y el teorema del valor central lo que permite explicar como a partir de una muestra se puede inferir algo acerca de una población, lo cual nos lleva a definir y elaborar una distribución de muestreo de medias muestrales que nos permite explicar el teorema del limite central y utilizar este teorema para encontrar las probabilidades de obtener las distintas medias maestrales de una población.
Pero es necesario tener conocimiento de ciertos datos de la población como la media, la desviación estándar o la forma de la población, pero a veces no se dispone de esta información.
En este caso es necesario hacer una estimación puntual que es un valor que se usa para estimar un valor poblacional. Pero una estimación puntual es un solo valor y se requiere un intervalo de valores a esto se denomina intervalote confianza y se espera que dentro de este intervalo se encuentre el parámetro poblacional buscado. También se utiliza una estimación mediante un intervalo, el cual es un rango de valores en el que se espera se encuentre el parámetro poblacional
En nuestro caso se desarrolla un procedimiento para probar la validez de una aseveración acerca de un parámetro poblacional este método es denominado Prueba de hipótesis para una muestra.
2.- HIPOTESIS Y PRUEBA DE HIPOTESIS
Tenemos que empezar por definir que es una hipótesis y que es prueba de hipótesis.
Hipótesis es una aseveración de una población elaborado con el propósito de poner aprueba, para verificar si la afirmación es razonable se usan datos.
En el análisis estadístico se hace una aseveración, es decir, se plantea una hipótesis, después se hacen las pruebas para verificar la aseveración o para determinar que no es verdadera.
Por tanto, la prueba de hipótesis es un procedimiento basado en la evidencia muestral y la teoría de probabilidad; se emplea para determinar si la hipótesis es una afirmación razonable.
Prueba de una hipótesis: se realiza mediante un procedimiento sistemático de cinco paso:
 Siguiendo este procedimiento sistemático, al llegar al paso cinco se puede o no rechazar la hipótesis, pero debemos de tener cuidado con esta determinación ya que en la consideración de estadística no proporciona evidencia de que algo sea verdadero. Esta prueba aporta una clase de prueba más allá de una duda razonable. Analizaremos cada paso en detalle
Siguiendo este procedimiento sistemático, al llegar al paso cinco se puede o no rechazar la hipótesis, pero debemos de tener cuidado con esta determinación ya que en la consideración de estadística no proporciona evidencia de que algo sea verdadero. Esta prueba aporta una clase de prueba más allá de una duda razonable. Analizaremos cada paso en detalle
Objetivo de la prueba de hipótesis.
El propósito de la prueba de hipótesis no es cuestionar el valor calculado del estadístico (muestral), sino hacer
un juicio con respecto a la diferencia entre estadístico de muestra y un valor planteado del parámetro.
3.- Procedimiento sistemático para una prueba de hipótesis de una muestra
.Paso 1: Plantear la hipótesis nula Ho y la hipótesis alternativa H1.
Cualquier investigación estadística implica la existencia de hipótesis o afirmaciones acerca de las poblaciones que se estudian.
La hipótesis nula (Ho) se refiere siempre a un valor especificado del parámetro de población, no a una estadística de muestra. La letra H significa hipótesis y el subíndice cero no hay diferencia. Por lo general hay un "no" en la hipótesis nula que indica que "no hay cambio" Podemos rechazar o aceptar Ho.
La hipótesis nula es una afirmación que no se rechaza a menos que los datos maestrales proporcionen evidencia convincente de que es falsa. El planteamiento de la hipótesis nula siempre contiene un signo de igualdad con respecto al valor especificado del parámetro.
La hipótesis alternativa (H1) es cualquier hipótesis que difiera de la hipótesis nula. Es una afirmación que se acepta si los datos maestrales proporcionan evidencia suficiente de que la hipótesis nula es falsa. Se le conoce también como la hipótesis de investigación. El planteamiento de la hipótesis alternativa nunca contiene un signo de igualdad con respecto al valor especificado del parámetro.
Paso 2: Seleccionar el nivel de significancia.
Nivel de significacia: Probabilidad de rechazar la hipótesis nula cuando es verdadera. Se le denota mediante la letra griega α, tambiιn es denominada como nivel de riesgo, este termino es mas adecuado ya que se corre el riesgo de rechazar la hipótesis nula, cuando en realidad es verdadera. Este nivel esta bajo el control de la persona que realiza la prueba.
Si suponemos que la hipótesis planteada es verdadera, entonces, el nivel de significación indicará la probabilidad de no aceptarla, es decir, estén fuera de área de aceptación. El nivel de confianza (1-α), indica la probabilidad de aceptar la hipótesis planteada, cuando es verdadera en la población.
 La distribución de muestreo de la estadística de prueba se divide en dos regiones, una región de rechazo (conocida como región crítica) y una región de no rechazo (aceptación). Si la estadística de prueba cae dentro de la región de aceptación, no se puede rechazar la hipótesis nula.
La distribución de muestreo de la estadística de prueba se divide en dos regiones, una región de rechazo (conocida como región crítica) y una región de no rechazo (aceptación). Si la estadística de prueba cae dentro de la región de aceptación, no se puede rechazar la hipótesis nula.
La región de rechazo puede considerarse como el conjunto de valores de la estadística de prueba que no tienen posibilidad de presentarse si la hipótesis nula es verdadera. Por otro lado, estos valores no son tan improbables de presentarse si la hipótesis nula es falsa. El valor crítico separa la región de no rechazo de la de rechazo.
Tipos de errores
Cualquiera sea la decisión tomada a partir de una prueba de hipótesis, ya sea de aceptación de la Ho o de la Ha, puede incurrirse en error:
Un error tipo I se presenta si la hipótesis nula Ho es rechazada cuando es verdadera y debía ser aceptada. La probabilidad de cometer un error tipo I se denomina con la letra alfa α
Un error tipo II, se denota con la letra griega β se presenta si la hipótesis nula es aceptada cuando de hecho es falsa y debía ser rechazada.
En cualquiera de los dos casos se comete un error al tomar una decisión equivocada.
En la siguiente tabla se muestran las decisiones que pueden tomar el investigador y las consecuencias posibles.
 Para que cualquier ensayo de hipótesis sea bueno, debe diseñarse de forma que minimice los errores de decisión. En la práctica un tipo de error puede tener más importancia que el otro, y así se tiene a conseguir poner una limitación al error de mayor importancia. La única forma de reducir ambos tipos de errores es incrementar el tamaño de la muestra, lo cual puede ser o no ser posible.
Para que cualquier ensayo de hipótesis sea bueno, debe diseñarse de forma que minimice los errores de decisión. En la práctica un tipo de error puede tener más importancia que el otro, y así se tiene a conseguir poner una limitación al error de mayor importancia. La única forma de reducir ambos tipos de errores es incrementar el tamaño de la muestra, lo cual puede ser o no ser posible.
La probabilidad de cometer un error de tipo II denotada con la letra griega beta β, depende de la diferencia entre los valores supuesto y real del parámetro de la población. Como es más fácil encontrar diferencias grandes, si la diferencia entre la estadística de muestra y el correspondiente parámetro de población es grande, la probabilidad de cometer un error de tipo II, probablemente sea pequeña.
El estudio y las conclusiones que obtengamos para una población cualquiera, se habrán apoyado exclusivamente en el análisis de una parte de ésta. De la probabilidad con la que estemos dispuestos a asumir estos errores, dependerá, por ejemplo, el tamaño de la muestra requerida. Las contrastaciones se apoyan en que los datos de partida siguen una distribución normal
Existe una relación inversa entre la magnitud de los errores α y β: conforme a aumenta, β disminuye. Esto obliga a establecer con cuidado el valor de a para las pruebas estadísticas. Lo ideal sería establecer α y β.En la práctica se establece el nivel α y para disminuir el Error β se incrementa el número de observaciones en la muestra, pues así se acortan los limites de confianza respecto a la hipótesis planteada .La meta de las pruebas estadísticas es rechazar la hipótesis planteada. En otras palabras, es deseable aumentar cuando ésta es verdadera, o sea, incrementar lo que se llama poder de la prueba (1- β)La aceptación de la hipótesis planteada debe interpretarse como que la información aleatoria de la muestra disponible no permite detectar la falsedad de esta hipótesis.
Paso 3: Cálculo del valor estadístico de prueba
Valor determinado a partir de la información muestral, que se utiliza para determinar si se rechaza la hipótesis nula., existen muchos estadísticos de prueba para nuestro caso utilizaremos los estadísticos z y t. La elección de uno de estos depende de la cantidad de muestras que se toman, si las muestras son de la prueba son iguales a 30 o mas se utiliza el estadístico z, en caso contrario se utiliza el estadístico t.
Tipos de prueba
a) Prueba bilateral o de dos extremos: la hipótesis planteada se formula con la igualdad
Ejemplo
H0 : µ = 200
H1 : µ ≠ 200
 b) Pruebas unilateral o de un extremo: la hipótesis planteada se formula con ≥ o ≤
b) Pruebas unilateral o de un extremo: la hipótesis planteada se formula con ≥ o ≤
H0 : µ ≥ 200 H0 : µ ≤ 200
H1 : µ < 200 H1 : µ > 200
 En las pruebas de hipótesis para la media (μ), cuando se conoce la desviación estándar (σ) poblacional, o cuando el valor de la muestra es grande (30 o más), el valor estadístico de prueba es z y se determina a partir de:
En las pruebas de hipótesis para la media (μ), cuando se conoce la desviación estándar (σ) poblacional, o cuando el valor de la muestra es grande (30 o más), el valor estadístico de prueba es z y se determina a partir de:
 El valor estadístico z, para muestra grande y desviación estándar poblacional desconocida se determina por la ecuación:
El valor estadístico z, para muestra grande y desviación estándar poblacional desconocida se determina por la ecuación:
 En la prueba para una media poblacional con muestra pequeña y desviación estándar poblacional desconocida se utiliza el valor estadístico t.
En la prueba para una media poblacional con muestra pequeña y desviación estándar poblacional desconocida se utiliza el valor estadístico t.
 Paso 4: Formular la regla de decisión
Paso 4: Formular la regla de decisión
SE establece las condiciones específicas en la que se rechaza la hipótesis nula y las condiciones en que no se rechaza la hipótesis nula. La región de rechazo define la ubicación de todos los valores que son tan grandes o tan pequeños, que la probabilidad de que se presenten bajo la suposición de que la hipótesis nula es verdadera, es muy remota
 Distribución muestral del valor estadístico z, con prueba de una cola a la derecha
Distribución muestral del valor estadístico z, con prueba de una cola a la derecha
Valor critico: Es el punto de división entre la región en la que se rechaza la hipótesis nula y la región en la que no se rechaza la hipótesis nula.
Paso 5: Tomar una decisión.
En este último paso de la prueba de hipótesis, se calcula el estadístico de prueba, se compara con el valor crítico y se toma la decisión de rechazar o no la hipótesis nula. Tenga presente que en una prueba de hipótesis solo se puede tomar una de dos decisiones: aceptar o rechazar la hipótesis nula. Debe subrayarse que siempre existe la posibilidad de rechazar la hipótesis nula cuando no debería haberse rechazado (error tipo I). También existe la posibilidad de que la hipótesis nula se acepte cuando debería haberse rechazado (error de tipo II).
4.- Ejemplo en la cual se indica el procedimiento para la prueba de hipótesis
Ejemplo
El jefe de la Biblioteca Especializada de la Facultad de Ingeniería Eléctrica y Electrónica de la UNAC manifiesta que el número promedio de lectores por día es de 350. Para confirmar o no este supuesto se controla la cantidad de lectores que utilizaron la biblioteca durante 30 días. Se considera el nivel de significancia de 0.05
Datos:
Solución: Se trata de un problema con una media poblacional: muestra grande y desviación estándar poblacional desconocida.
Paso 01: Seleccionamos la hipótesis nula y la hipótesis alternativa
Ho: μ═350
Ha: μ≠ 350
Paso 02: Nivel de confianza o significancia 95%
α═0.05
Paso 03: Calculamos o determinamos el valor estadístico de prueba
De los datos determinamos: que el estadístico de prueba es t, debido a que el numero de muestras es igual a 30, conocemos la media de la población, pero la desviación estándar de la población es desconocida, en este caso determinamos la desviación estándar de la muestra y la utilizamos en la formula reemplazando a la desviación estándar de la población.
Calculamos la desviación estándar muestral y la media de la muestra empleando Excel, lo cual se muestra en el cuadro que sigue.
Paso 04: Formulación de la regla de decisión.
La regla de decisión la formulamos teniendo en cuenta que esta es una prueba de dos colas, la mitad de 0.05, es decir 0.025, esta en cada cola. el área en la que no se rechaza Ho esta entre las dos colas, es por consiguiente 0.95. El valor critico para 0.05 da un valor de Zc = 1.96.
Por consiguiente la regla de decisión: es rechazar la hipótesis nula y aceptar la hipótesis alternativa, si el valor Z calculado no queda en la región comprendida entre -1.96 y +1.96. En caso contrario no se rechaza la hipótesis nula si Z queda entre -1.96 y +1.96.
Paso 05: Toma de decisión.
En este ultimo paso comparamos el estadístico de prueba calculado mediante el Software Minitab que es igual a Z = 2.38 y lo comparamos con el valor critico de Zc = 1.96. Como el estadístico de prueba calculado cae a la derecha del valor critico de Z, se rechaza Ho. Por tanto no se confirma el supuesto del Jefe de la Biblioteca.
One-Sample Z
Test of mu = 350 vs not = 350
The assumed standard deviation = 52.414
N Mean SE Mean 95% CI Z P
30 372.800 9.569 (354.044, 391.556) 2.38 0.017

 Conclusiones:
Conclusiones:
Dentro del estudio de la inferencia estadística, se describe como se puede tomar una muestra aleatoria y a partir de esta muestra estimar el valor de un parámetro poblacional en la cual se puede emplear el método de muestreo y el teorema del valor central lo que permite explicar como a partir de una muestra se puede inferir algo acerca de una población, lo cual nos lleva a definir y elaborar una distribución de muestreo de medias muestrales que nos permite explicar el teorema del limite central y utilizar este teorema para encontrar las probabilidades de obtener las distintas medias maestrales de una población.
Pero es necesario tener conocimiento de ciertos datos de la población como la media, la desviación estándar o la forma de la población, pero a veces no se dispone de esta información.
En este caso es necesario hacer una estimación puntual que es un valor que se usa para estimar un valor poblacional. Pero una estimación puntual es un solo valor y se requiere un intervalo de valores a esto se denomina intervalote confianza y se espera que dentro de este intervalo se encuentre el parámetro poblacional buscado. También se utiliza una estimación mediante un intervalo, el cual es un rango de valores en el que se espera se encuentre el parámetro poblacional
En nuestro caso se desarrolla un procedimiento para probar la validez de una aseveración acerca de un parámetro poblacional este método es denominado Prueba de hipótesis para una muestra.
2.- HIPOTESIS Y PRUEBA DE HIPOTESIS
Tenemos que empezar por definir que es una hipótesis y que es prueba de hipótesis.
Hipótesis es una aseveración de una población elaborado con el propósito de poner aprueba, para verificar si la afirmación es razonable se usan datos.
En el análisis estadístico se hace una aseveración, es decir, se plantea una hipótesis, después se hacen las pruebas para verificar la aseveración o para determinar que no es verdadera.
Por tanto, la prueba de hipótesis es un procedimiento basado en la evidencia muestral y la teoría de probabilidad; se emplea para determinar si la hipótesis es una afirmación razonable.
Prueba de una hipótesis: se realiza mediante un procedimiento sistemático de cinco paso:
Objetivo de la prueba de hipótesis.
El propósito de la prueba de hipótesis no es cuestionar el valor calculado del estadístico (muestral), sino hacer
un juicio con respecto a la diferencia entre estadístico de muestra y un valor planteado del parámetro.
3.- Procedimiento sistemático para una prueba de hipótesis de una muestra
.Paso 1: Plantear la hipótesis nula Ho y la hipótesis alternativa H1.
Cualquier investigación estadística implica la existencia de hipótesis o afirmaciones acerca de las poblaciones que se estudian.
La hipótesis nula (Ho) se refiere siempre a un valor especificado del parámetro de población, no a una estadística de muestra. La letra H significa hipótesis y el subíndice cero no hay diferencia. Por lo general hay un "no" en la hipótesis nula que indica que "no hay cambio" Podemos rechazar o aceptar Ho.
La hipótesis nula es una afirmación que no se rechaza a menos que los datos maestrales proporcionen evidencia convincente de que es falsa. El planteamiento de la hipótesis nula siempre contiene un signo de igualdad con respecto al valor especificado del parámetro.
La hipótesis alternativa (H1) es cualquier hipótesis que difiera de la hipótesis nula. Es una afirmación que se acepta si los datos maestrales proporcionan evidencia suficiente de que la hipótesis nula es falsa. Se le conoce también como la hipótesis de investigación. El planteamiento de la hipótesis alternativa nunca contiene un signo de igualdad con respecto al valor especificado del parámetro.
Paso 2: Seleccionar el nivel de significancia.
Nivel de significacia: Probabilidad de rechazar la hipótesis nula cuando es verdadera. Se le denota mediante la letra griega α, tambiιn es denominada como nivel de riesgo, este termino es mas adecuado ya que se corre el riesgo de rechazar la hipótesis nula, cuando en realidad es verdadera. Este nivel esta bajo el control de la persona que realiza la prueba.
Si suponemos que la hipótesis planteada es verdadera, entonces, el nivel de significación indicará la probabilidad de no aceptarla, es decir, estén fuera de área de aceptación. El nivel de confianza (1-α), indica la probabilidad de aceptar la hipótesis planteada, cuando es verdadera en la población.
La región de rechazo puede considerarse como el conjunto de valores de la estadística de prueba que no tienen posibilidad de presentarse si la hipótesis nula es verdadera. Por otro lado, estos valores no son tan improbables de presentarse si la hipótesis nula es falsa. El valor crítico separa la región de no rechazo de la de rechazo.
Tipos de errores
Cualquiera sea la decisión tomada a partir de una prueba de hipótesis, ya sea de aceptación de la Ho o de la Ha, puede incurrirse en error:
Un error tipo I se presenta si la hipótesis nula Ho es rechazada cuando es verdadera y debía ser aceptada. La probabilidad de cometer un error tipo I se denomina con la letra alfa α
Un error tipo II, se denota con la letra griega β se presenta si la hipótesis nula es aceptada cuando de hecho es falsa y debía ser rechazada.
En cualquiera de los dos casos se comete un error al tomar una decisión equivocada.
En la siguiente tabla se muestran las decisiones que pueden tomar el investigador y las consecuencias posibles.
La probabilidad de cometer un error de tipo II denotada con la letra griega beta β, depende de la diferencia entre los valores supuesto y real del parámetro de la población. Como es más fácil encontrar diferencias grandes, si la diferencia entre la estadística de muestra y el correspondiente parámetro de población es grande, la probabilidad de cometer un error de tipo II, probablemente sea pequeña.
El estudio y las conclusiones que obtengamos para una población cualquiera, se habrán apoyado exclusivamente en el análisis de una parte de ésta. De la probabilidad con la que estemos dispuestos a asumir estos errores, dependerá, por ejemplo, el tamaño de la muestra requerida. Las contrastaciones se apoyan en que los datos de partida siguen una distribución normal
Existe una relación inversa entre la magnitud de los errores α y β: conforme a aumenta, β disminuye. Esto obliga a establecer con cuidado el valor de a para las pruebas estadísticas. Lo ideal sería establecer α y β.En la práctica se establece el nivel α y para disminuir el Error β se incrementa el número de observaciones en la muestra, pues así se acortan los limites de confianza respecto a la hipótesis planteada .La meta de las pruebas estadísticas es rechazar la hipótesis planteada. En otras palabras, es deseable aumentar cuando ésta es verdadera, o sea, incrementar lo que se llama poder de la prueba (1- β)La aceptación de la hipótesis planteada debe interpretarse como que la información aleatoria de la muestra disponible no permite detectar la falsedad de esta hipótesis.
Paso 3: Cálculo del valor estadístico de prueba
Valor determinado a partir de la información muestral, que se utiliza para determinar si se rechaza la hipótesis nula., existen muchos estadísticos de prueba para nuestro caso utilizaremos los estadísticos z y t. La elección de uno de estos depende de la cantidad de muestras que se toman, si las muestras son de la prueba son iguales a 30 o mas se utiliza el estadístico z, en caso contrario se utiliza el estadístico t.
Tipos de prueba
a) Prueba bilateral o de dos extremos: la hipótesis planteada se formula con la igualdad
Ejemplo
H0 : µ = 200
H1 : µ ≠ 200
H0 : µ ≥ 200 H0 : µ ≤ 200
H1 : µ < 200 H1 : µ > 200
SE establece las condiciones específicas en la que se rechaza la hipótesis nula y las condiciones en que no se rechaza la hipótesis nula. La región de rechazo define la ubicación de todos los valores que son tan grandes o tan pequeños, que la probabilidad de que se presenten bajo la suposición de que la hipótesis nula es verdadera, es muy remota
Valor critico: Es el punto de división entre la región en la que se rechaza la hipótesis nula y la región en la que no se rechaza la hipótesis nula.
Paso 5: Tomar una decisión.
En este último paso de la prueba de hipótesis, se calcula el estadístico de prueba, se compara con el valor crítico y se toma la decisión de rechazar o no la hipótesis nula. Tenga presente que en una prueba de hipótesis solo se puede tomar una de dos decisiones: aceptar o rechazar la hipótesis nula. Debe subrayarse que siempre existe la posibilidad de rechazar la hipótesis nula cuando no debería haberse rechazado (error tipo I). También existe la posibilidad de que la hipótesis nula se acepte cuando debería haberse rechazado (error de tipo II).
4.- Ejemplo en la cual se indica el procedimiento para la prueba de hipótesis
Ejemplo
El jefe de la Biblioteca Especializada de la Facultad de Ingeniería Eléctrica y Electrónica de la UNAC manifiesta que el número promedio de lectores por día es de 350. Para confirmar o no este supuesto se controla la cantidad de lectores que utilizaron la biblioteca durante 30 días. Se considera el nivel de significancia de 0.05
Datos:
| Día | Usuarios | Día | Usuarios | Día | Usuario |
| 1 | 356 | 11 |
305
| 21 |
429
|
| 2 | 427 | 12 |
413
| 22 |
376
|
| 3 | 387 | 13 |
391
| 23 |
328
|
| 4 | 510 | 14 |
380
| 24 |
411
|
| 5 | 288 | 15 |
382
| 25 |
397
|
| 6 | 290 | 16 |
389
| 26 |
365
|
| 7 | 320 | 17 |
405
| 27 |
405
|
| 8 | 350 | 18 |
293
| 28 |
369
|
| 9 | 403 | 19 |
276
| 29 |
429
|
| 10 | 329 | 20 |
417
| 30 |
364
|
Solución: Se trata de un problema con una media poblacional: muestra grande y desviación estándar poblacional desconocida.
Paso 01: Seleccionamos la hipótesis nula y la hipótesis alternativa
Ho: μ═350
Ha: μ≠ 350
Paso 02: Nivel de confianza o significancia 95%
α═0.05
Paso 03: Calculamos o determinamos el valor estadístico de prueba
De los datos determinamos: que el estadístico de prueba es t, debido a que el numero de muestras es igual a 30, conocemos la media de la población, pero la desviación estándar de la población es desconocida, en este caso determinamos la desviación estándar de la muestra y la utilizamos en la formula reemplazando a la desviación estándar de la población.
Columna1
| |
| Media |
372.8
|
| Error típico |
9.56951578
|
| Mediana |
381
|
| Moda |
405
|
| Desviación estándar |
52.4143965
|
| Varianza de la muestra |
2747.26897
|
| Curtosis |
0.36687081
|
| Coeficiente de asimetría |
0.04706877
|
| Rango |
234
|
| Mínimo |
276
|
| Máximo |
510
|
| Suma |
11184
|
| Cuenta |
30
|
| Nivel de confianza (95.0%) |
19.571868
|
La regla de decisión la formulamos teniendo en cuenta que esta es una prueba de dos colas, la mitad de 0.05, es decir 0.025, esta en cada cola. el área en la que no se rechaza Ho esta entre las dos colas, es por consiguiente 0.95. El valor critico para 0.05 da un valor de Zc = 1.96.
Por consiguiente la regla de decisión: es rechazar la hipótesis nula y aceptar la hipótesis alternativa, si el valor Z calculado no queda en la región comprendida entre -1.96 y +1.96. En caso contrario no se rechaza la hipótesis nula si Z queda entre -1.96 y +1.96.
Paso 05: Toma de decisión.
En este ultimo paso comparamos el estadístico de prueba calculado mediante el Software Minitab que es igual a Z = 2.38 y lo comparamos con el valor critico de Zc = 1.96. Como el estadístico de prueba calculado cae a la derecha del valor critico de Z, se rechaza Ho. Por tanto no se confirma el supuesto del Jefe de la Biblioteca.
One-Sample Z
Test of mu = 350 vs not = 350
The assumed standard deviation = 52.414
N Mean SE Mean 95% CI Z P
30 372.800 9.569 (354.044, 391.556) 2.38 0.017
- Se rechaza la hipótesis nula (Ho), se acepta la hipótesis alterna (H1) a un nivel de significancia de α = 0.05. La prueba resultó ser significativa.
- La evidencia estadística no permite aceptar la aceptar la hipótesis nula.
Pruebas de hipotesis
Afirmación acerca los parámetros de la población.
Etapas Básicas en Pruebas de Hipótesis.
Al realizar pruebas de hipótesis, se parte de un valor supuesto (hipotético) parámetro poblacional. Después de recolectar una muestra aleatoria, se compara la estadística muestral, así como la media (x), con el parámetro hipotético, se compara con una supuesta media poblacional (). Después se acepta o se rechaza el valor hipotético, según proceda. Se rechaza el valor hipotético sólo si el resultado muestral resulta muy poco probable cuando la hipótesis es cierta.
1.- Planear la hipótesis nula y la hipótesis alternativa. La hipótesis nula (H0) es el valor hipotético del parámetro que se compra con el resultado muestral resulta muy poco probable cuando la hipótesis es cierta.
Etapa 2.- Especificar el nivel de significancia que se va a utilizar. El nivel de significancia del 5%, entonces se rechaza la hipótesis nula solamente si el resultado muestral es tan diferente del valor hipotético que una diferencia de esa magnitud o mayor, pudiera ocurrir aleatoria mente con una probabilidad de 1.05 o menos.
Etapa 3.- Elegir la estadística de prueba. La estadística de prueba puede ser la estadística muestral (el estimador no segado del parámetro que se prueba) o una versión transformada de esa estadística muestral. Por ejemplo, el valor hipotético de una media poblacional, se toma la media de una muestra aleatoria de esa distribución normal, entonces es común que se transforme la media en un valor z el cual, a su vez, sirve como estadística de prueba.
Consecuencias de las Decisiones en Pruebas de Hipótesis.
Etapa 4.- Establecer el valor o valores críticos de la estadística de prueba. Habiendo especificado la hipótesis nula, el nivel de significancia y la estadística de prueba que se van a utilizar, se produce a establecer el o los valores críticos de estadística de prueba. Puede o más de esos valores, dependiendo de si se va a realizar una prueba de uno o dos extremos.
Etapa 5.- Determinar el valor real de la estadística de prueba. Por ejemplo, al probar un valor hipotético de la media poblacional, se toma una muestra aleatoria y se determina el valor de la media muestral. Si el valor crítico que se establece es un valor de z, entonces se transforma la media muestral en un valor de z.
Etapa 6.- Tomar la decisión. Se compara el valor observado de la estadística muestral con el valor (o valores) críticos de la estadística de prueba. Después se acepta o se rechaza la hipótesis nula. Si se rechaza ésta, se acepta la alternativa; a su vez, esta decisión tendrá efecto sobre otras decisiones de los administradores operativos, como por ejemplo, mantener o no un estándar de desempeño o cuál de dos estrategias de mercadotecnia utilizar.
La distribución apropiada de la prueba estadística se divide en dos regiones: una de rechazo y una de no rechazo. Si la prueba estadística en esta última región no se puede rechazar la hipótesis nula y se llega a la conclusión de que el proceso funciona correctamente.
Al tomar la decisión con respecto a la hipótesis nula, se debe determinar el valor crítico en la distribución estadística que divide la región del rechazo (en la cual la hipótesis nula no se puede rechazar) de la región de rechazo. A hora bien el valor crítico depende del tamaño de la región de rechazo.
PASOS DE LA PRUEBA DE HIPÓTESIS
Hipótesis Estadística:
Al intentar alcanzar una decisión, es útil hacer hipótesis (o conjeturas) sobre la población aplicada.
Tales hipótesis, que pueden ser o no ciertas, se llaman hipótesis estadísticas.
Son, en general, enunciados acerca de las distribuciones de probabilidad de las poblaciones.
Hipótesis Nula.
En muchos casos formulamos una hipótesis estadística con el único propósito de rechazarla o invalidarla. Así, si queremos decidir si una moneda está trucada, formulamos la hipótesis de que la moneda es buena (o sea p = 0,5, donde p es la probabilidad de cara).
Analógicamente, si deseamos decidir si un procedimiento es mejor que otro, formulamos la hipótesis de que no hay diferencia entre ellos (o sea. Que cualquier diferencia observada se debe simplemente a fluctuaciones en el muestreo de la misma población). Tales hipótesis se suelen llamar hipótesis nula y se denotan por Ho.
Para todo tipo de investigación en la que tenemos dos o más grupos, se establecerá una hipótesis nula.
La hipótesis nula es aquella que nos dice que no existen diferencias significativas entre los grupos.
Por ejemplo, supongamos que un investigador cree que si un grupo de jóvenes se somete a un entrenamiento intensivo de natación, éstos serán mejores nadadores que aquellos que no recibieron entrenamiento. Para demostrar su hipótesis toma al azar una muestra de jóvenes, y también al azar los distribuye en dos grupos: uno que llamaremos experimental, el cual recibirá entrenamiento, y otro que no recibirá entrenamiento alguno, al que llamaremos control. La hipótesis nula señalará que no hay diferencia en el desempeño de la natación entre el grupo de jóvenes que recibió el entrenamiento y el que no lo recibió.
Una hipótesis nula es importante por varias razones:
Es una hipótesis que se acepta o se rechaza según el resultado de la investigación.
El hecho de contar con una hipótesis nula ayuda a determinar si existe una diferencia entre los grupos, si esta diferencia es significativa, y si no se debió al azar.
No toda investigación precisa de formular hipótesis nula. Recordemos que la hipótesis nula es aquella por la cual indicamos que la información a obtener es contraria a la hipótesis de trabajo.
Al formular esta hipótesis, se pretende negar la variable independiente. Es decir, se enuncia que la causa determinada como origen del problema fluctúa, por tanto, debe rechazarse como tal.
Otro ejemplo:
Hipótesis: el aprendizaje de los niños se relaciona directamente con su edad.
Hipótesis Alternativa.
Toda hipótesis que difiere de una dada se llamará una hipótesis alternativa. Por ejemplo: Si una hipótesis es p = 0,5, hipótesis alternativa podrían ser p = 0,7, p " 0,5 ó p > 0,5.
Una hipótesis alternativa a la hipótesis nula se denotará por H1.
Los trabajos de índole descriptiva generalmente presentan hipótesis del tipo "todos los X poseen, en alguna medida, las característica Y". Por ejemplo, podemos decir que todas las naciones poseen algún comercio internacional, y dedicarnos a describir, cuantificando, las relaciones comerciales entre ellas. También podemos hacer afirmaciones del tipo "X pertenece al tipo Y", como cuando decimos que una tecnología es capital - intensiva. En estos casos, describimos, clasificándolo, el objeto de nuestro interés, incluyéndolo en un tipo ideal complejo de orden superior.
Por último, podemos construir hipótesis del tipo "X produce (o afecta) a Y", donde estaremos en presencia de una relación entre variables.
Errores de tipo I y de tipo II.
Si rechazamos una hipótesis cuando debiera ser aceptada, diremos que se ha cometido un error de tipo I.
Por otra parte, si aceptamos una hipótesis que debiera ser rechazada, diremos que se cometió un error de tipo II.
En ambos casos, se ha producido un juicio erróneo.
Para que las reglas de decisión (o no contraste de hipótesis) sean buenos, deben diseñarse de modo que minimicen los errores de la decisión; y no es una cuestión sencilla, porque para cualquier tamaño de la muestra, un intento de disminuir un tipo de error suele ir acompañado de un crecimiento del otro tipo. En la práctica, un tipo de error puede ser más grave que el otro, y debe alcanzarse un compromiso que disminuya el error más grave.
La única forma de disminuir ambos a la vez es aumentar el tamaño de la muestra que no siempre es posible.
Niveles de Significación.
Al contrastar una cierta hipótesis, la máxima probabilidad con la que estamos dispuesto a correr el riesgo de cometerán error de tipo I, se llama nivel de significación.
Esta probabilidad, denota a menudo por se, suele especificar antes de tomar la muestra, de manera que los resultados obtenidos no influyan en nuestra elección.
En la práctica, es frecuente un nivel de significación de 0,05 ó 0,01, si bien se une otros valores. Si por ejemplo se escoge el nivel de significación 0,05 (ó 5%) al diseñar una regla de decisión, entonces hay unas cinco (05) oportunidades entre 100 de rechazar la hipótesis cuando debiera haberse aceptado; Es decir, tenemos un 95% de confianza de que hemos adoptado la decisión correcta. En tal caso decimos que la hipótesis ha sido rechazada al nivel de significación 0,05, lo cual quiere decir que tal hipótesis tiene una probabilidad 0,05 de ser falsa.
Prueba de Uno y Dos Extremos.
Cuando estudiamos ambos valores estadísticos es decir, ambos lados de la media lo llamamos prueba de uno y dos extremos o contraste de una y dos colas.
Con frecuencia no obstante, estaremos interesados tan sólo en valores extremos a un lado de la media (o sea, en uno de los extremos de la distribución), tal como sucede cuando se contrasta la hipótesis de que un proceso es mejor que otro (lo cual no es lo mismo que contrastar si un proceso es mejor o peor que el otro) tales contrastes se llaman unilaterales, o de un extremo. En tales situaciones, la región crítica es una región situada a un lado de la distribución, con área igual al nivel de significación.
Curva Característica Operativa Y Curva De Potencia
Podemos limitar un error de tipo I eligiendo adecuadamente el nivel de significancia. Es posible evitar el riesgo de cometer el error tipo II simplemente no aceptando nunca la hipótesis, pero en muchas aplicaciones prácticas esto es inviable. En tales casos, se suele recurrir a curvas características de operación o curvas de potencia que son gráficos que muestran las probabilidades de error de tipo II bajo diversas hipótesis. Proporcionan indicaciones de hasta que punto un test dado nos permitirá evitar un error de tipo II; es decir, nos indicarán la potencia de un test a la hora de prevenir decisiones erróneas. Son útiles en el diseño de experimentos por que sugieren entre otras cosas el tamaño de muestra a manejar.
Pruebas de hipótesis para la media y proporciones
Debido a la dificultad de explicar este tema se enfocará un problema basado en un estudio en una fábrica de llantas.
En este problema la fábrica de llantas tiene dos turnos de operarios, turno de día y turno mixto. Se selecciona una muestra aleatoria de 100 llantas producidas por cada turno para ayudar al gerente a sacar conclusiones de cada una de las siguientes preguntas:
1.- ¿Es la duración promedio de las llantas producidas en el turno de día igual a 25 000 millas?
2.- ¿Es la duración promedio de las llantas producidas en el turno mixto menor de 25 000 millas?
3.- ¿Se revienta más de un 8% de las llantas producidas por el turno de día antes de las 10 000 millas?
Prueba De Hipótesis Para La Media
En la fábrica de llantas la hipótesis nula y alternativa para el problema se plantearon como sigue:
Ho: μ = 25 000
H1: μ ≠ 25 000
 Si se considera la desviación estándar σ las llantas producidas en el turno de día, entonces, con base en el teorema de limite central, la distribución en el muestreo de la media seguiría la distribución normal, y la prueba estadística que esta basada en la diferencia entre la media
Si se considera la desviación estándar σ las llantas producidas en el turno de día, entonces, con base en el teorema de limite central, la distribución en el muestreo de la media seguiría la distribución normal, y la prueba estadística que esta basada en la diferencia entre la media  de la muestra y la media μ hipotιtica se encontrara como sigue:
de la muestra y la media μ hipotιtica se encontrara como sigue:
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Si el tamaño de la región α de rechazo se estableciera en 5% entonces se podrían determinar los valores críticos de la distribución. Dado que la región de rechazo esta dividida en las dos colas de la distribución, el 5% se divide en dos partes iguales de 2.5%.
Dado que ya se tiene la distribución normal, los valores críticos se pueden expresar en unidades de desviación. Una región de rechazo de 0.25 en cada cola de la distribución normal, da por resultado un área de .475 entre la media hipotética y el valor crítico. Si se busca está área en la distribución normal, se encuentra que los valores críticos que dividen las regiones de rechazo y no rechazo son + 1.96 y - 1.96
 Por tanto, la regla para decisión sería:
Por tanto, la regla para decisión sería:
Rechazar Ho si Z > + 1.96
O si Z < - 1.96
De lo contrario, no rechazar Ho
No obstante, en la mayor parte de los casos se desconoce la desviación estándar de la población. La desviación estándar se estima al calcular S, la desviación estándar de la muestra. Si se supone que la población es normal la distribución en el muestreo de la media seguiría una distribución t con n-1 grados de libertad. En la práctica, se a encontrado que siempre y cuando el tamaño de la muestra no sea muy pequeño y la población no este muy sesgada, la distribución t da una buena aproximación a la distribución de muestra de la media. La prueba estadística para determinar la diferencia entre la media
de la población. La desviación estándar se estima al calcular S, la desviación estándar de la muestra. Si se supone que la población es normal la distribución en el muestreo de la media seguiría una distribución t con n-1 grados de libertad. En la práctica, se a encontrado que siempre y cuando el tamaño de la muestra no sea muy pequeño y la población no este muy sesgada, la distribución t da una buena aproximación a la distribución de muestra de la media. La prueba estadística para determinar la diferencia entre la media  de la muestra y la media
de la muestra y la media  de la población cuando se utiliza la desviación estándar S de la muestra, se expresa con:
de la población cuando se utiliza la desviación estándar S de la muestra, se expresa con:

 Para una muestra de 100, si se selecciona un nivel de significancía
Para una muestra de 100, si se selecciona un nivel de significancía  de .05, los valores críticos de la distribución t con 100-1= 99 grados de libertad se puede obtener como se indica en la siguiente tabla:
de .05, los valores críticos de la distribución t con 100-1= 99 grados de libertad se puede obtener como se indica en la siguiente tabla:
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Como esta prueba de dos colas, la región de rechazo de .05 se vuelve a dividir en dos partes iguales de .025 cada una. Con el uso de las tablas para t, los valores críticos son –1.984 y +1.984. la regla para la decisión es:
Rechazar Ho si >+1.984
>+1.984
O si - 1.984
- 1.984
De lo contrario, no rechazar Ho
 Los resultados de la muestra para el turno de día fueron
Los resultados de la muestra para el turno de día fueron  =25 430 millas,
=25 430 millas, =4 000 millas y
=4 000 millas y  = 100. Puesto que se esta probando si la media es diferente a 25 000 millas, se tiene con la ecuación
= 100. Puesto que se esta probando si la media es diferente a 25 000 millas, se tiene con la ecuación
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Dado que = 1.075, se ve que -1.984 < +1.075 < + 1.984, entonces no se rechaza Ho.
= 1.075, se ve que -1.984 < +1.075 < + 1.984, entonces no se rechaza Ho.
Por ello, la de cisión de no rechazar la hipótesis nula Ho. En conclusión es que la duración promedio de las llantas es 25 000 millas. A fin de tener en cuenta la posibilidad de un error de tipo II, este enunciado se puede redactar como "no hay pruebas de que la duración promedio de las llantas sea diferente a 25 000 millas en las llantas producidas en el turno de día".
Prueba De Hipótesis Para Proporciones
El concepto de prueba de hipótesis se puede utilizar para probar hipótesis en relación con datos cualitativos. Por ejemplo, en el problema anterior el gerente de la fabrica de llantas quería determinar la proporción de llantas que se reventaban antes de 10,000 millas. Este es un ejemplo de una variable cualitativa, dado que se desea llegar a conclusiones en cuanto a la proporción de los valores que tienen una característica particular.
El gerente de la fábrica de llantas quiere que la calidad de llantas producidas, sea lo bastante alta para que muy pocas se revienten antes de las 10,000 millas. Si más de un 8% de las llantas se revientan antes de las 10,000 millas, se llegaría a concluir que el proceso no funciona correctamente. La hipótesis nula y alternativa se pueden expresar como sigue:
Ho: p .08 (funciona correctamente)
.08 (funciona correctamente)
H1: p > .08 (no funciona correctamente)

La prueba estadística se puede expresar en términos de la proporción de éxitos como sigue:
En donde
Para ver el gráfico seleccione la opción "Descargar" del menú superior
p = proporción de éxitos de la hipótesis nula
Ahora se determinará si el proceso funciona correctamente para las llantas producidas para el turno de día. Los resultados del turno de día índican que cinco llantas en una muestra de 100 se reventaron antes de 10,000 millas para este problema, si se selecciona un nivel de significancía de .05, las regiones de rechazo y no rechazo se establecerían como a continuación se muestra:
de .05, las regiones de rechazo y no rechazo se establecerían como a continuación se muestra:
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Y la regla de decisión sería:
Rechazar Ho si > + 1.645; de lo contrario no rechazar Ho.
> + 1.645; de lo contrario no rechazar Ho.
Con los datos que se tienen,
 =
=  = .05
= .05
Y entonces,
 =
=  =
=  =
=  = -1.107
= -1.107
Z -1.107 < + 1.645; por tanto no rechazar Ho.
-1.107 < + 1.645; por tanto no rechazar Ho.
La hipótesis nula no se rechazaría por que la prueba estadística no ha caído en la región de rechazo. Se llegaría a la conclusión de que no hay pruebas de que más del 8% de las llantas producidas en el turno de día se revienten antes de 10,000 millas. El gerente no ha encontrado ninguna prueba de que ocurra un número excesivo de reventones en las llantas producidas en el turno de día.
http://cosmech.tripod.com/index.htm
Pruebas de Hipótesis
Una hipótesis estadística es una suposición hecha con respecto a la función de distribución de una variable aleatoria.
Para establecer la verdad o falsedad de una hipótesis estadística con certeza total, será necesario examinar toda la población. En la mayoría de las situaciones reales no es posible o practico efectuar este examen, y el camino mas aconsejable es tomar una muestra aleatoria de la población y en base a ella, decidir si la hipótesis es verdadera o falsa.
En la prueba de una hipótesis estadística, es costumbre declarar la hipótesis como verdadera si la probabilidad calculada excede el valor tabular llamado el nivel de significación y se declara falsa si la probabilidad calculada es menor que el valor tabular.
La prueba a realizar dependerá del tamaño de las muestras, de la homogeneidad de las varianzas y de la dependencia o no de las variables.
Si las muestras a probar involucran a más de 30 observaciones, se aplicará la prueba de Z, si las muestras a evaluar involucran un número de observaciones menor o igual que 30 se emplea la prueba de t de student. La fórmula de cálculo depende de si las varianzas son homogéneas o heterogéneas, si el número de observaciones es igual o diferente, o si son variables dependientes.
Para determinar la homogeneidad de las varianzas se toma la varianza mayor y se divide por la menor, este resultado es un estimado de la F de Fisher. Luego se busca en la tabla de F usando como numerador los grados de libertad (n-1) de la varianza mayor y como denominador (n-1) de la varianza menor para encontrar la F de Fisher tabular. Si la F estimada es menor que la F tabular se declara que las varianzas son homogéneas. Si por el contrario, se declaran las varianzas heterogéneas. Cuando son variables dependientes (el valor de una depende del valor de la otra), se emplea la técnica de pruebas pareadas.
Como en general estas pruebas se aplican a dos muestras, se denominarán a y b para referirse a ellas, así entenderemos por:
 Ejemplo:
Ejemplo:
La altura promedio de 50 palmas que tomaron parte de un ensayo es de 78 cm. con una desviación estándar de 2.5 cm.; mientras que otras 50 palmas que no forman parte del ensayo tienen media y desviación estándar igual a 77.3 y 2.8 cm.
 Se desea probar la hipótesis de que las palmas que participan en el ensayo son más altas que las otras.
Se desea probar la hipótesis de que las palmas que participan en el ensayo son más altas que las otras.
Consultando el valor z de la tabla a 95% de probabilidad se tiene que es 1.96, por lo consiguiente, el valor z calculado no fue mayor al valor de la tabla y entonces se declara la prueba no significativa.
Conclusión: Las alturas promedio de los 2 grupos de palmas son iguales y la pequeña diferencia observada en favor al primer grupo se debe al azar.
2.-Caso de número igual de observaciones y varianzas homogéneas.
 Ejemplo:
Ejemplo:
Se plantó cierto experimento en 24 parcelas para probar el efecto de la presencia o ausencia de K en el rendimiento de palma.
Peso medio del racimo (Kg.)
 s2a = 5918.5 - (266)2/12 = 2.02
s2a = 5918.5 - (266)2/12 = 2.02
11
s2b = 8346 - (316)2/12 = 2.24
11
Se busca en la tabla de t de student con 2 (n-1) grados de libertad o sea 22, y se encuentra que el valor tabular es de 2.074 al 95% de probabilidad, el cual es menor que la t calculada y por lo tanto se declara la prueba significativa.
Conclusión: La diferencia entre promedios observados es atribuible al efecto de tratamiento (K), por haberse conseguido un resultado significativo.
3.-Caso de igual número de observaciones y varianzas heterogéneas.
 Ejemplo:
Ejemplo:
Se plantó cierto experimento en 24 parcelas con dos clases de semillas: semilla mezclada y semilla DxP seleccionada. Se desea saber si el rendimiento observado por la semilla seleccionada difiere a la otra.
Producción de palma: TM/ha/año
Para ver la tabla seleccione la opción "Descargar" del menú superior

s2a = 1748.61 - (144.5)2/12 = 0.78
11
s2b = 4001.14 - (216.2)2/12 = 9.63
11
Consultando la tabla de t con n-1 grados de libertad (11) se encuentra un valor de 2.201, por lo tanto, la diferencia se declara significativa.
Conclusión: El rendimiento observado por las plantas de semilla seleccionada fue significativamente superior a las otras.
4.-Caso de diferente número de observaciones y varianzas homogéneas
 Ejemplo:
Ejemplo:
Se tomó una área de terreno distribuida en 22 parcelas y a 13 de ellas se les aplicó un fertilizante nitrogenado para medir el efecto del N en el crecimiento.
Área foliar de la hoja # 17 en m2
Para ver la tabla seleccione la opción "Descargar" del menú superior
 s2a = 968.93 - (112.1)2/13 = 0.19
s2a = 968.93 - (112.1)2/13 = 0.19
12
s2b = 390.84 - (59.2)2/9 = 0.18
8
s2c = 12(0.19) + 8(0.18) = 0.19
20
Consultando la tabla de t con n-1 grados de libertad (11) se encuentra un valor de 2.201, por lo tanto, la diferencia se declara significativa.
Conclusión: El rendimiento observado por las plantas de semilla seleccionada fue significativamente superior a las otras.
Ejemplo:
Se tomó una área de terreno distribuida en 22 parcelas y a 13 de ellas se les aplicó un fertilizante nitrogenado para medir el efecto del N en el crecimiento.
Área foliar de la hoja # 17 en m2
Para ver la tabla seleccione la opción "Descargar" del menú superior
s2a = 968.93 - (112.1)2/13 = 0.19
12
s2b = 390.84 - (59.2)2/9 = 0.18
8
s2c = 12(0.19) + 8(0.18) = 0.19
20
Consultando la tabla con (na-1) + (nb-1) o sea (20) grados de libertad, se obtiene el valor tabular de 2.086, el cual es menor que la t calculada, por lo tanto la diferencia se declara significativa.
Conclusión: La diferencia detectada en estas dos muestras es atribuible a la aplicación del fertilizante nitrogenado.
5.- Caso de diferente número de observaciones y varianzas heterogéneas.
 En este caso, la tc es comparada con la tg (t generada), que a diferencia de los casos anteriores, hay que calcularla.
En este caso, la tc es comparada con la tg (t generada), que a diferencia de los casos anteriores, hay que calcularla.
 Donde: ta y tb son los valores de la tabla con n-1 grados de libertad para a y b respectivamente
Donde: ta y tb son los valores de la tabla con n-1 grados de libertad para a y b respectivamente
Ejemplo:
Se tomaron 2 muestras de palma comercial de orígenes diferentes y se midió el porcentaje de almendra en el racimo en ambas muestras, el objeto es probar si las muestras son diferentes genéticamente o no.
Porcentaje de almendra
Para ver la tabla seleccione la opción "Descargar" del menú superior
s2a = 225.02 - (53)2/14 = 1.88
13
 s2b = 192.26 - (43.80)2/10 = 0.05
s2b = 192.26 - (43.80)2/10 = 0.05
9

En este caso la t generada (tg), reemplaza la t de la tabla y como la tc es menor que la tg, la diferencia se declara No significativa.
Conclusión: La diferencia observada entre promedios es atribuible únicamente a errores de muestreo o variabilidad natural, y no a diferencias genéticas.
6.-Caso de muestras pareadas(de variables dependientes)
En este caso, se asume que las muestras han sido distribuidas por pares.
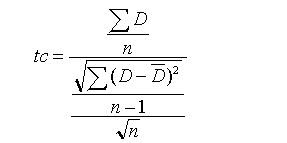 Ejemplo: Se tomaron 12 foliolos de palma joven y a cada uno se le trató la mitad con Benlate para medir la inhibición del crecimiento de hongos.
Ejemplo: Se tomaron 12 foliolos de palma joven y a cada uno se le trató la mitad con Benlate para medir la inhibición del crecimiento de hongos.
Magnitud del dano
Sin Con
n Benlate Benlate D = X - Y D2
Para ver la tabla seleccione la opción "Descargar" del menú superior
 Consultando la tabla con n-1 grados de libertad se obtiene el valor tabular de 2.201, por lo tanto, la diferencia se declara significativa.
Consultando la tabla con n-1 grados de libertad se obtiene el valor tabular de 2.201, por lo tanto, la diferencia se declara significativa.
Conclusión: De la prueba se desprende que el tratamiento con benlate redujo significativamente la incidencia de hongos.
Utilidad de las hipótesis:
El uso y formulación correcta de las hipótesis le permiten al investigador poner a prueba aspectos de la realidad, disminuyendo la distorsión que pudieran producir sus propios deseos o gustos. Pueden ser sometidas a prueba y demostrarse como probablemente correctas o incorrectas sin que interfieran los valores o creencias del individuo.


Etapas Básicas en Pruebas de Hipótesis.
Al realizar pruebas de hipótesis, se parte de un valor supuesto (hipotético) parámetro poblacional. Después de recolectar una muestra aleatoria, se compara la estadística muestral, así como la media (x), con el parámetro hipotético, se compara con una supuesta media poblacional (). Después se acepta o se rechaza el valor hipotético, según proceda. Se rechaza el valor hipotético sólo si el resultado muestral resulta muy poco probable cuando la hipótesis es cierta.
1.- Planear la hipótesis nula y la hipótesis alternativa. La hipótesis nula (H0) es el valor hipotético del parámetro que se compra con el resultado muestral resulta muy poco probable cuando la hipótesis es cierta.
Etapa 2.- Especificar el nivel de significancia que se va a utilizar. El nivel de significancia del 5%, entonces se rechaza la hipótesis nula solamente si el resultado muestral es tan diferente del valor hipotético que una diferencia de esa magnitud o mayor, pudiera ocurrir aleatoria mente con una probabilidad de 1.05 o menos.
Etapa 3.- Elegir la estadística de prueba. La estadística de prueba puede ser la estadística muestral (el estimador no segado del parámetro que se prueba) o una versión transformada de esa estadística muestral. Por ejemplo, el valor hipotético de una media poblacional, se toma la media de una muestra aleatoria de esa distribución normal, entonces es común que se transforme la media en un valor z el cual, a su vez, sirve como estadística de prueba.
Consecuencias de las Decisiones en Pruebas de Hipótesis.
| Decisiones Posibles | Situaciones Posibles | ||
| La hipótesis nula es verdadera | La hipótesis nula es falsa | ||
| Aceptar la Hipótesis Nula | Se acepta correctamente | Error II | |
| Rechazar la Hipótesis Nula | Error tipo I | Se rechaza correctamente | |
Etapa 5.- Determinar el valor real de la estadística de prueba. Por ejemplo, al probar un valor hipotético de la media poblacional, se toma una muestra aleatoria y se determina el valor de la media muestral. Si el valor crítico que se establece es un valor de z, entonces se transforma la media muestral en un valor de z.
Etapa 6.- Tomar la decisión. Se compara el valor observado de la estadística muestral con el valor (o valores) críticos de la estadística de prueba. Después se acepta o se rechaza la hipótesis nula. Si se rechaza ésta, se acepta la alternativa; a su vez, esta decisión tendrá efecto sobre otras decisiones de los administradores operativos, como por ejemplo, mantener o no un estándar de desempeño o cuál de dos estrategias de mercadotecnia utilizar.
La distribución apropiada de la prueba estadística se divide en dos regiones: una de rechazo y una de no rechazo. Si la prueba estadística en esta última región no se puede rechazar la hipótesis nula y se llega a la conclusión de que el proceso funciona correctamente.
Al tomar la decisión con respecto a la hipótesis nula, se debe determinar el valor crítico en la distribución estadística que divide la región del rechazo (en la cual la hipótesis nula no se puede rechazar) de la región de rechazo. A hora bien el valor crítico depende del tamaño de la región de rechazo.
PASOS DE LA PRUEBA DE HIPÓTESIS
- Expresar la hipótesis nula
- Expresar la hipótesis alternativa
- Especificar el nivel de significancía
- Determinar el tamaño de la muestra
- Establecer los valores críticos que establecen las de rechazo de las de no rechazo.
- Determinar la prueba estadística.
- Coleccionar los datos y calcular el valor de la muestra de la prueba estadística apropiada.
- Determinar si la prueba estadística ha sido en la zona de rechazo a una de no rechazo.
- Determinar la decisión estadística.
- Expresar la decisión estadística en términos del problema.
Hipótesis Estadística:
Al intentar alcanzar una decisión, es útil hacer hipótesis (o conjeturas) sobre la población aplicada.
Tales hipótesis, que pueden ser o no ciertas, se llaman hipótesis estadísticas.
Son, en general, enunciados acerca de las distribuciones de probabilidad de las poblaciones.
Hipótesis Nula.
En muchos casos formulamos una hipótesis estadística con el único propósito de rechazarla o invalidarla. Así, si queremos decidir si una moneda está trucada, formulamos la hipótesis de que la moneda es buena (o sea p = 0,5, donde p es la probabilidad de cara).
Analógicamente, si deseamos decidir si un procedimiento es mejor que otro, formulamos la hipótesis de que no hay diferencia entre ellos (o sea. Que cualquier diferencia observada se debe simplemente a fluctuaciones en el muestreo de la misma población). Tales hipótesis se suelen llamar hipótesis nula y se denotan por Ho.
Para todo tipo de investigación en la que tenemos dos o más grupos, se establecerá una hipótesis nula.
La hipótesis nula es aquella que nos dice que no existen diferencias significativas entre los grupos.
Por ejemplo, supongamos que un investigador cree que si un grupo de jóvenes se somete a un entrenamiento intensivo de natación, éstos serán mejores nadadores que aquellos que no recibieron entrenamiento. Para demostrar su hipótesis toma al azar una muestra de jóvenes, y también al azar los distribuye en dos grupos: uno que llamaremos experimental, el cual recibirá entrenamiento, y otro que no recibirá entrenamiento alguno, al que llamaremos control. La hipótesis nula señalará que no hay diferencia en el desempeño de la natación entre el grupo de jóvenes que recibió el entrenamiento y el que no lo recibió.
Una hipótesis nula es importante por varias razones:
Es una hipótesis que se acepta o se rechaza según el resultado de la investigación.
El hecho de contar con una hipótesis nula ayuda a determinar si existe una diferencia entre los grupos, si esta diferencia es significativa, y si no se debió al azar.
No toda investigación precisa de formular hipótesis nula. Recordemos que la hipótesis nula es aquella por la cual indicamos que la información a obtener es contraria a la hipótesis de trabajo.
Al formular esta hipótesis, se pretende negar la variable independiente. Es decir, se enuncia que la causa determinada como origen del problema fluctúa, por tanto, debe rechazarse como tal.
Otro ejemplo:
Hipótesis: el aprendizaje de los niños se relaciona directamente con su edad.
Hipótesis Alternativa.
Toda hipótesis que difiere de una dada se llamará una hipótesis alternativa. Por ejemplo: Si una hipótesis es p = 0,5, hipótesis alternativa podrían ser p = 0,7, p " 0,5 ó p > 0,5.
Una hipótesis alternativa a la hipótesis nula se denotará por H1.
- Al responder a un problema, es muy conveniente proponer otras hipótesis en que aparezcan variables independientes distintas de las primeras que formulamos. Por tanto, para no perder tiempo en búsquedas inútiles, es necesario hallar diferentes hipótesis alternativas como respuesta a un mismo problema y elegir entre ellas cuáles y en qué orden vamos a tratar su comprobación.
Los trabajos de índole descriptiva generalmente presentan hipótesis del tipo "todos los X poseen, en alguna medida, las característica Y". Por ejemplo, podemos decir que todas las naciones poseen algún comercio internacional, y dedicarnos a describir, cuantificando, las relaciones comerciales entre ellas. También podemos hacer afirmaciones del tipo "X pertenece al tipo Y", como cuando decimos que una tecnología es capital - intensiva. En estos casos, describimos, clasificándolo, el objeto de nuestro interés, incluyéndolo en un tipo ideal complejo de orden superior.
Por último, podemos construir hipótesis del tipo "X produce (o afecta) a Y", donde estaremos en presencia de una relación entre variables.
Errores de tipo I y de tipo II.
Si rechazamos una hipótesis cuando debiera ser aceptada, diremos que se ha cometido un error de tipo I.
Por otra parte, si aceptamos una hipótesis que debiera ser rechazada, diremos que se cometió un error de tipo II.
En ambos casos, se ha producido un juicio erróneo.
Para que las reglas de decisión (o no contraste de hipótesis) sean buenos, deben diseñarse de modo que minimicen los errores de la decisión; y no es una cuestión sencilla, porque para cualquier tamaño de la muestra, un intento de disminuir un tipo de error suele ir acompañado de un crecimiento del otro tipo. En la práctica, un tipo de error puede ser más grave que el otro, y debe alcanzarse un compromiso que disminuya el error más grave.
La única forma de disminuir ambos a la vez es aumentar el tamaño de la muestra que no siempre es posible.
Niveles de Significación.
Al contrastar una cierta hipótesis, la máxima probabilidad con la que estamos dispuesto a correr el riesgo de cometerán error de tipo I, se llama nivel de significación.
Esta probabilidad, denota a menudo por se, suele especificar antes de tomar la muestra, de manera que los resultados obtenidos no influyan en nuestra elección.
En la práctica, es frecuente un nivel de significación de 0,05 ó 0,01, si bien se une otros valores. Si por ejemplo se escoge el nivel de significación 0,05 (ó 5%) al diseñar una regla de decisión, entonces hay unas cinco (05) oportunidades entre 100 de rechazar la hipótesis cuando debiera haberse aceptado; Es decir, tenemos un 95% de confianza de que hemos adoptado la decisión correcta. En tal caso decimos que la hipótesis ha sido rechazada al nivel de significación 0,05, lo cual quiere decir que tal hipótesis tiene una probabilidad 0,05 de ser falsa.
Prueba de Uno y Dos Extremos.
Cuando estudiamos ambos valores estadísticos es decir, ambos lados de la media lo llamamos prueba de uno y dos extremos o contraste de una y dos colas.
Con frecuencia no obstante, estaremos interesados tan sólo en valores extremos a un lado de la media (o sea, en uno de los extremos de la distribución), tal como sucede cuando se contrasta la hipótesis de que un proceso es mejor que otro (lo cual no es lo mismo que contrastar si un proceso es mejor o peor que el otro) tales contrastes se llaman unilaterales, o de un extremo. En tales situaciones, la región crítica es una región situada a un lado de la distribución, con área igual al nivel de significación.
Curva Característica Operativa Y Curva De Potencia
Podemos limitar un error de tipo I eligiendo adecuadamente el nivel de significancia. Es posible evitar el riesgo de cometer el error tipo II simplemente no aceptando nunca la hipótesis, pero en muchas aplicaciones prácticas esto es inviable. En tales casos, se suele recurrir a curvas características de operación o curvas de potencia que son gráficos que muestran las probabilidades de error de tipo II bajo diversas hipótesis. Proporcionan indicaciones de hasta que punto un test dado nos permitirá evitar un error de tipo II; es decir, nos indicarán la potencia de un test a la hora de prevenir decisiones erróneas. Son útiles en el diseño de experimentos por que sugieren entre otras cosas el tamaño de muestra a manejar.
Pruebas de hipótesis para la media y proporciones
Debido a la dificultad de explicar este tema se enfocará un problema basado en un estudio en una fábrica de llantas.
En este problema la fábrica de llantas tiene dos turnos de operarios, turno de día y turno mixto. Se selecciona una muestra aleatoria de 100 llantas producidas por cada turno para ayudar al gerente a sacar conclusiones de cada una de las siguientes preguntas:
1.- ¿Es la duración promedio de las llantas producidas en el turno de día igual a 25 000 millas?
2.- ¿Es la duración promedio de las llantas producidas en el turno mixto menor de 25 000 millas?
3.- ¿Se revienta más de un 8% de las llantas producidas por el turno de día antes de las 10 000 millas?
Prueba De Hipótesis Para La Media
En la fábrica de llantas la hipótesis nula y alternativa para el problema se plantearon como sigue:
Ho: μ = 25 000
H1: μ ≠ 25 000
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Si el tamaño de la región α de rechazo se estableciera en 5% entonces se podrían determinar los valores críticos de la distribución. Dado que la región de rechazo esta dividida en las dos colas de la distribución, el 5% se divide en dos partes iguales de 2.5%.
Dado que ya se tiene la distribución normal, los valores críticos se pueden expresar en unidades de desviación. Una región de rechazo de 0.25 en cada cola de la distribución normal, da por resultado un área de .475 entre la media hipotética y el valor crítico. Si se busca está área en la distribución normal, se encuentra que los valores críticos que dividen las regiones de rechazo y no rechazo son + 1.96 y - 1.96
Rechazar Ho si Z > + 1.96
O si Z < - 1.96
De lo contrario, no rechazar Ho
No obstante, en la mayor parte de los casos se desconoce la desviación estándar
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Como esta prueba de dos colas, la región de rechazo de .05 se vuelve a dividir en dos partes iguales de .025 cada una. Con el uso de las tablas para t, los valores críticos son –1.984 y +1.984. la regla para la decisión es:
Rechazar Ho si
O si
De lo contrario, no rechazar Ho
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Dado que
Por ello, la de cisión de no rechazar la hipótesis nula Ho. En conclusión es que la duración promedio de las llantas es 25 000 millas. A fin de tener en cuenta la posibilidad de un error de tipo II, este enunciado se puede redactar como "no hay pruebas de que la duración promedio de las llantas sea diferente a 25 000 millas en las llantas producidas en el turno de día".
Prueba De Hipótesis Para Proporciones
El concepto de prueba de hipótesis se puede utilizar para probar hipótesis en relación con datos cualitativos. Por ejemplo, en el problema anterior el gerente de la fabrica de llantas quería determinar la proporción de llantas que se reventaban antes de 10,000 millas. Este es un ejemplo de una variable cualitativa, dado que se desea llegar a conclusiones en cuanto a la proporción de los valores que tienen una característica particular.
El gerente de la fábrica de llantas quiere que la calidad de llantas producidas, sea lo bastante alta para que muy pocas se revienten antes de las 10,000 millas. Si más de un 8% de las llantas se revientan antes de las 10,000 millas, se llegaría a concluir que el proceso no funciona correctamente. La hipótesis nula y alternativa se pueden expresar como sigue:
Ho: p
H1: p > .08 (no funciona correctamente)
La prueba estadística se puede expresar en términos de la proporción de éxitos como sigue:
En donde
Para ver el gráfico seleccione la opción "Descargar" del menú superior
p = proporción de éxitos de la hipótesis nula
Ahora se determinará si el proceso funciona correctamente para las llantas producidas para el turno de día. Los resultados del turno de día índican que cinco llantas en una muestra de 100 se reventaron antes de 10,000 millas para este problema, si se selecciona un nivel de significancía
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Y la regla de decisión sería:
Rechazar Ho si
Con los datos que se tienen,
Y entonces,
= = Z
La hipótesis nula no se rechazaría por que la prueba estadística no ha caído en la región de rechazo. Se llegaría a la conclusión de que no hay pruebas de que más del 8% de las llantas producidas en el turno de día se revienten antes de 10,000 millas. El gerente no ha encontrado ninguna prueba de que ocurra un número excesivo de reventones en las llantas producidas en el turno de día.
http://cosmech.tripod.com/index.htm
Pruebas de Hipótesis
Una hipótesis estadística es una suposición hecha con respecto a la función de distribución de una variable aleatoria.
Para establecer la verdad o falsedad de una hipótesis estadística con certeza total, será necesario examinar toda la población. En la mayoría de las situaciones reales no es posible o practico efectuar este examen, y el camino mas aconsejable es tomar una muestra aleatoria de la población y en base a ella, decidir si la hipótesis es verdadera o falsa.
En la prueba de una hipótesis estadística, es costumbre declarar la hipótesis como verdadera si la probabilidad calculada excede el valor tabular llamado el nivel de significación y se declara falsa si la probabilidad calculada es menor que el valor tabular.
La prueba a realizar dependerá del tamaño de las muestras, de la homogeneidad de las varianzas y de la dependencia o no de las variables.
Si las muestras a probar involucran a más de 30 observaciones, se aplicará la prueba de Z, si las muestras a evaluar involucran un número de observaciones menor o igual que 30 se emplea la prueba de t de student. La fórmula de cálculo depende de si las varianzas son homogéneas o heterogéneas, si el número de observaciones es igual o diferente, o si son variables dependientes.
Para determinar la homogeneidad de las varianzas se toma la varianza mayor y se divide por la menor, este resultado es un estimado de la F de Fisher. Luego se busca en la tabla de F usando como numerador los grados de libertad (n-1) de la varianza mayor y como denominador (n-1) de la varianza menor para encontrar la F de Fisher tabular. Si la F estimada es menor que la F tabular se declara que las varianzas son homogéneas. Si por el contrario, se declaran las varianzas heterogéneas. Cuando son variables dependientes (el valor de una depende del valor de la otra), se emplea la técnica de pruebas pareadas.
Como en general estas pruebas se aplican a dos muestras, se denominarán a y b para referirse a ellas, así entenderemos por:
- na al número de elementos de la muestra a
- nb al número de elementos de la muestra b
- xb al promedio de la muestra b
- s2a la varianza de la muestra a
- Y así sucesivamente
- Caso de muestras grandes (n>30)
- Caso de na = nb y s2a = s2b
- Caso de na = nb y s2a <> s2b
- Caso de na <> nb y s2a = s2b
- Caso de na <> nb y s2a <> s2b
- Caso de variables dependientes
La altura promedio de 50 palmas que tomaron parte de un ensayo es de 78 cm. con una desviación estándar de 2.5 cm.; mientras que otras 50 palmas que no forman parte del ensayo tienen media y desviación estándar igual a 77.3 y 2.8 cm.
Consultando el valor z de la tabla a 95% de probabilidad se tiene que es 1.96, por lo consiguiente, el valor z calculado no fue mayor al valor de la tabla y entonces se declara la prueba no significativa.
Conclusión: Las alturas promedio de los 2 grupos de palmas son iguales y la pequeña diferencia observada en favor al primer grupo se debe al azar.
2.-Caso de número igual de observaciones y varianzas homogéneas.
Se plantó cierto experimento en 24 parcelas para probar el efecto de la presencia o ausencia de K en el rendimiento de palma.
Peso medio del racimo (Kg.)
| n | a | b | a2 | b2 |
| 1 | 20.0 | 24.0 | 400.00 | 576.00 |
| 2 | 24.0 | 28.0 | 576.00 | 784.00 |
| 3 | 21.0 | 25.0 | 441.00 | 625.00 |
| 4 | 22.0 | 25.0 | 484.00 | 625.00 |
| 5 | 23.0 | 27.0 | 529.00 | 729.00 |
| 6 | 24.0 | 27.5 | 576.00 | 756.25 |
| 7 | 22.5 | 28.0 | 506.25 | 784.00 |
| 8 | 22.0 | 26.0 | 484.00 | 576.00 |
| 9 | 21.5 | 26.0 | 462.25 | 676.00 |
| 10 | 20.0 | 24.5 | 400.00 | 600.25 |
| 11 | 22.0 | 26.5 | 484.00 | 702.25 |
| 12 | 24.0 | 28.5 | 576.00 | 812.25 |
| Suma | 266 | 316 | 5918.5 | 8346 |
| Promedio | 22.16 | 26.33 |
11
s2b = 8346 - (316)2/12 = 2.24
11
Se busca en la tabla de t de student con 2 (n-1) grados de libertad o sea 22, y se encuentra que el valor tabular es de 2.074 al 95% de probabilidad, el cual es menor que la t calculada y por lo tanto se declara la prueba significativa.
Conclusión: La diferencia entre promedios observados es atribuible al efecto de tratamiento (K), por haberse conseguido un resultado significativo.
3.-Caso de igual número de observaciones y varianzas heterogéneas.
Se plantó cierto experimento en 24 parcelas con dos clases de semillas: semilla mezclada y semilla DxP seleccionada. Se desea saber si el rendimiento observado por la semilla seleccionada difiere a la otra.
Producción de palma: TM/ha/año
Para ver la tabla seleccione la opción "Descargar" del menú superior
s2a = 1748.61 - (144.5)2/12 = 0.78
11
s2b = 4001.14 - (216.2)2/12 = 9.63
11
Consultando la tabla de t con n-1 grados de libertad (11) se encuentra un valor de 2.201, por lo tanto, la diferencia se declara significativa.
Conclusión: El rendimiento observado por las plantas de semilla seleccionada fue significativamente superior a las otras.
4.-Caso de diferente número de observaciones y varianzas homogéneas
Se tomó una área de terreno distribuida en 22 parcelas y a 13 de ellas se les aplicó un fertilizante nitrogenado para medir el efecto del N en el crecimiento.
Área foliar de la hoja # 17 en m2
Para ver la tabla seleccione la opción "Descargar" del menú superior
s2a = 968.93 - (112.1)2/13 = 0.1912
s2b = 390.84 - (59.2)2/9 = 0.18
8
s2c = 12(0.19) + 8(0.18) = 0.19
20
Consultando la tabla de t con n-1 grados de libertad (11) se encuentra un valor de 2.201, por lo tanto, la diferencia se declara significativa.
Conclusión: El rendimiento observado por las plantas de semilla seleccionada fue significativamente superior a las otras.
Ejemplo:
Se tomó una área de terreno distribuida en 22 parcelas y a 13 de ellas se les aplicó un fertilizante nitrogenado para medir el efecto del N en el crecimiento.
Área foliar de la hoja # 17 en m2
Para ver la tabla seleccione la opción "Descargar" del menú superior
s2a = 968.93 - (112.1)2/13 = 0.1912
s2b = 390.84 - (59.2)2/9 = 0.18
8
s2c = 12(0.19) + 8(0.18) = 0.19
20
Consultando la tabla con (na-1) + (nb-1) o sea (20) grados de libertad, se obtiene el valor tabular de 2.086, el cual es menor que la t calculada, por lo tanto la diferencia se declara significativa.
Conclusión: La diferencia detectada en estas dos muestras es atribuible a la aplicación del fertilizante nitrogenado.
5.- Caso de diferente número de observaciones y varianzas heterogéneas.
Ejemplo:
Se tomaron 2 muestras de palma comercial de orígenes diferentes y se midió el porcentaje de almendra en el racimo en ambas muestras, el objeto es probar si las muestras son diferentes genéticamente o no.
Porcentaje de almendra
Para ver la tabla seleccione la opción "Descargar" del menú superior
s2a = 225.02 - (53)2/14 = 1.88
13
s2b = 192.26 - (43.80)2/10 = 0.059
En este caso la t generada (tg), reemplaza la t de la tabla y como la tc es menor que la tg, la diferencia se declara No significativa.
Conclusión: La diferencia observada entre promedios es atribuible únicamente a errores de muestreo o variabilidad natural, y no a diferencias genéticas.
6.-Caso de muestras pareadas(de variables dependientes)
En este caso, se asume que las muestras han sido distribuidas por pares.
Magnitud del dano
Sin Con
n Benlate Benlate D = X - Y D2
Para ver la tabla seleccione la opción "Descargar" del menú superior
Conclusión: De la prueba se desprende que el tratamiento con benlate redujo significativamente la incidencia de hongos.
Utilidad de las hipótesis:
El uso y formulación correcta de las hipótesis le permiten al investigador poner a prueba aspectos de la realidad, disminuyendo la distorsión que pudieran producir sus propios deseos o gustos. Pueden ser sometidas a prueba y demostrarse como probablemente correctas o incorrectas sin que interfieran los valores o creencias del individuo.
Suscribirse a:
Entradas (Atom)